Hi everyone,
Hope you’re doing good.
The issue: new SQL ID with bad execution plan
A couple of months ago, I had a call from a client regarding a performance issue.
They had a query running against a table with acceptable performance.
On one specific day, they added one column to that table and included this column as part of the output for their query.
Since then, they noticed that the “new” query was performing poorly. They called me a few weeks after they noticed that.
Checking the history for the new SQL_ID using the sqlstat.sql script, we observed that the new SQL_ID, cvjwh9tmwcfsu, is using the PLAN_HASH_VALUE 2632938434. As we can observe below:
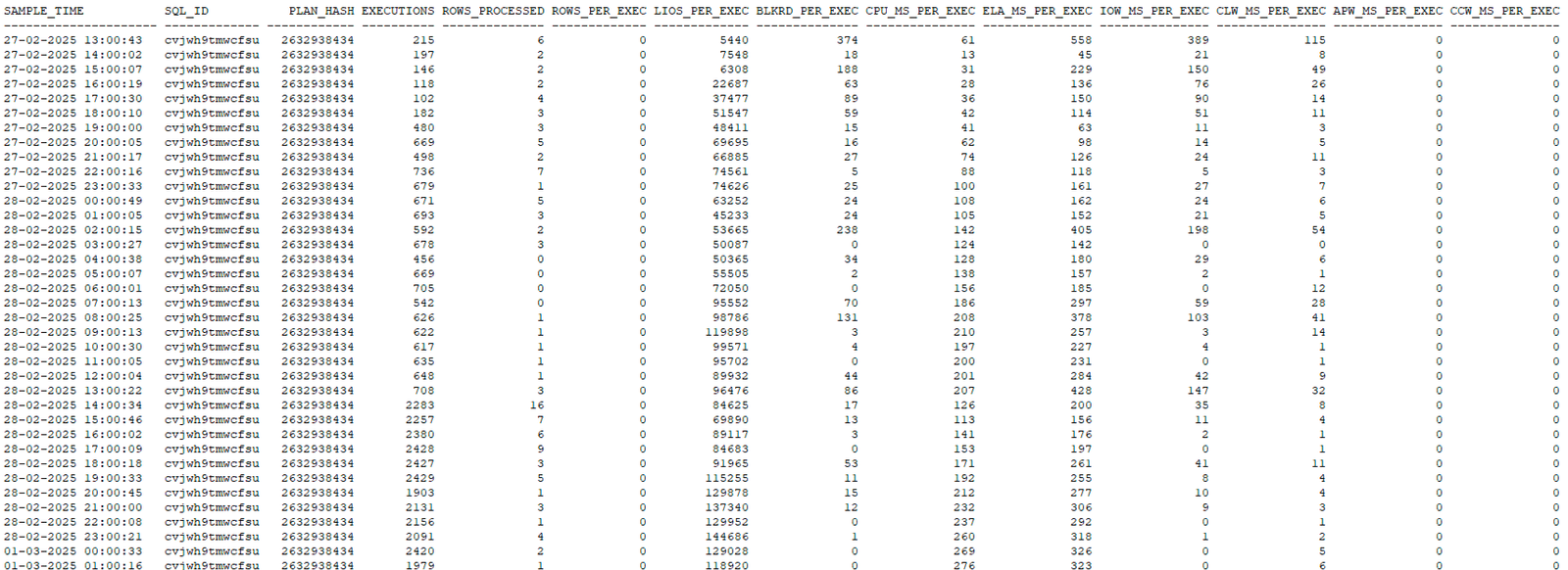
Using the same script, sqlstat.sql, we observed the old SQL_ID, b7s3d3y5sj4wr, with different PLAN_HASH_VALUES: 2086437475 and 1084416631. We noticed that this PLAN_HASH_VALUE (1084416631) is really good—better than the new plan. As we can observe below:

We do know that the only difference in the query is the new column they added to the table.
So, the idea here is:
- Apply the good plan from the old SQL_ID to the new SQL_ID.
Basically, we can achieve this using two approaches:
- Using SQL Profiles;
- Using SQL Plan Baselines.
SQL Profiles are usually used as a firefighting resource, as they do not guarantee plan stability like SQL Plan Baselines do.
The original script: coe_load_sql_baseline.sql
There is a very good script called coe_load_sql_baseline.sql created by Carlos Sierra, and it is part of SQLT, which you can download here: All About the SQLT Diagnostic Tool (Doc ID 215187.1)
The script coe_load_sql_baseline has the capability to apply the plan (using SQL Plan Baseline) to the original SQL from a modified SQL. Example:
You have your SQL with a specific plan that is not performing well, and the developer doesn’t have the ability to change the SQL (because the software is a “black box”). What the developer can do is run the SQL with an Optimizer Hint, for example. Then, you can apply the plan from the “modified” SQL to the “original” SQL through a SQL Plan Baseline.
In our case, we say that the “original” SQL is the new one, with the column added to the table, running with the bad execution plan. The “modified” SQL is the old one, which had the good execution plan.
The script coe_load_sql_baseline has some prerequisites:
- The original SQL must be in cache or AWR;
- The modified SQL must be in cache;
- Connect as a user with DBA privilege, for example, SYSTEM.
So, the script’s capabilities are:
- Find the original SQL in cache or AWR;
- Find the modified SQL in cache;
- Create a SQL Plan Baseline from the modified SQL and apply it to the original SQL;
- Export (conventional export) the staging pack table in case you need to transport the SQL Plan Baseline to another database.
Let’s remember, the client called me a few weeks after the new SQL had been introduced. So, the “modified” (which is the old SQL) was not in cache anymore. Therefore, the script coe_load_sql_baseline would fail with the message: PHV 1084416631 for modified SQL_ID b7s3d3y5sj4wr was not found in memory (gv$sql).
With that in mind, I thought it would be great if coe_load_sql_baseline had the capability to find plans from both memory and/or AWR.
One more point: if you are using TDE and the staging pack table is stored in an encrypted tablespace, the conventional export will fail with EXP-00111: Table YYYYY resides in an Encrypted Tablespace ZZZZZZ and will not be exported.
So, it would be great to have the script updated, adding the capability to look for the plan in memory or AWR and to consider Data Pump Export instead of Conventional Export.
Keep in mind that if the coe_load_sql_baseline.sql script finds the required plans in memory, then no license is required. However, if it retrieves plans from the Automatic Workload Repository (AWR), a Diagnostic Pack license is required.
The solution: vini_coe_load_sql_baseline.sql
So, I’m really happy and honored to share that I created a customized version of coe_load_sql_baseline, adding the enhancements listed above. I’m calling it: vini_coe_load_sql_baseline.sql
This script has some prerequisites:
- The original SQL must be in cache or AWR;
- The modified SQL must be in cache or AWR;
- You must connect as a user with DBA privileges (for example, SYSTEM);
- An object directory called DATA_PUMP_DIR must exist in the database, its physical path must be valid on the operating system, and the user must have read and write privileges on that directory object.
Here, you can find a flow diagram how script will work:
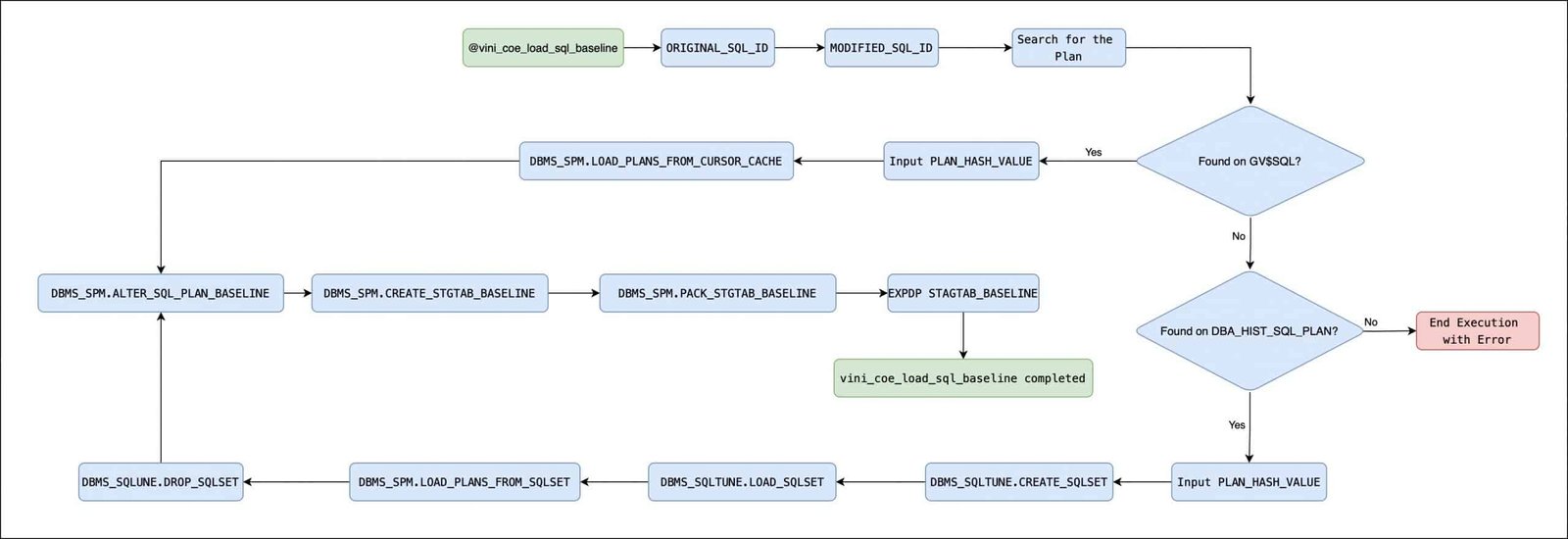
OK, let’s execute the script. Below, there is a breakdown of how the script works. After the breakdown, you’ll find the complete output from the execution:
@vini_coe_load_sql_baseline
The script will display the database user currently connected, and then prompt for three parameters—just like the original coe_load_sql_baseline:
- The original SQL_ID (in our case, the “new” one);
- The modified SQL_ID (in our case, the “old” one with the good execution plan);
At this point, the script will check for execution plans—first in memory (GV$SQL), and then in AWR (DBA_HIST_SQL_PLAN). If any plan is found, it will display performance data for the plan found either in GV$SQL or DBA_HIST_SQLSTAT. Then, you can select the plan you’d like to use:
- The plan you’d like to use in the SQL Plan Baseline.
After that, the baseline will be loaded from the cursor cache if the plan is found in GV$SQL. Otherwise, a SQL Tuning Set (STS) will be created, the plan will be loaded from AWR into the STS, a SQL Plan Baseline will be created, the STS will be dropped (for cleanup purposes), a staging table for the baseline will be created, the baseline will be packed into the staging table, and finally, the table will be exported and ready for transport to other databases—if needed.
OK, let’s move on to the script output:
CONNECTED_USER
------------------------------
MARCUS
Parameter 1:
ORIGINAL_SQL_ID (required)
Enter value for 1: cvjwh9tmwcfsu
Parameter 2:
MODIFIED_SQL_ID (required)
Enter value for 2: b7s3d3y5sj4wr
Available Plan Hash Values:
Using DBA_HIST_SQLSTAT:
PHV: 1084446631 AVG_ET_SECS: .083
PHV: 2086437475 AVG_ET_SECS: .158
Parameter 3:
PLAN_HASH_VALUE (required)
Enter value for 3: 1084446631
Found plan in AWR between snap_ids: 87412 and 88251
Plans Loaded from AWR: 1
sys_sql_handle: "SQL_20cc2a9baaffebc0"
sys_plan_name: "SQL_PLAN_21m1amfpgzuy00ac23035"
1 plan(s) modified description: "ORIGINAL:CVJWH9TMWCFSU MODIFIED:B7S3D3Y5SJ4WR PHV:1084446631 CREATED BY VINI_COE_LOAD_SQL_BASELINE.SQL"
dropping staging table "STGTAB_BASELINE_CVJWH9TMWCFSU"
creating staging table "STGTAB_BASELINE_CVJWH9TMWCFSU"
packaging new sql baseline into staging table "STGTAB_BASELINE_CVJWH9TMWCFSU"
1 plan(s) packaged
SQL>REM
SQL>REM SQL Plan Baseline
SQL>REM ~~~~~~~~~~~~~~~~~
SQL>REM
SQL>SELECT signature, sql_handle, plan_name, enabled, accepted, fixed--, reproduced (avail on 11.2.0.2)
2 FROM dba_sql_plan_baselines WHERE plan_name = :plan_name;
SIGNATURE SQL_HANDLE PLAN_NAME ENA ACC FIX
-------------------- ------------------------------ -------------------------------------------------------------------------------------------------------------------------------- --- --- ---
2363310752539864000 SQL_20cc2a9baaffebc0 SQL_PLAN_21m1amfpgzuy00ac23035 YES YES NO
SQL>SELECT description
2 FROM dba_sql_plan_baselines WHERE plan_name = :plan_name;
DESCRIPTION
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ORIGINAL:CVJWH9TMWCFSU MODIFIED:B7S3D3Y5SJ4WR PHV:1084446631 CREATED BY VINI_COE_LOAD_SQL_BASELINE.SQL
SQL>SET ECHO OFF;
****************************************************************************
* Enter MARCUS password to export staging table STGTAB_BASELINE_cvjwh9tmwcfsu
****************************************************************************
Export: Release 19.0.0.0.0 - Production on Wed Mar 24 20:01:39 2025
Version 19.24.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
Password:
Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
FLASHBACK automatically enabled to preserve database integrity.
Starting "MARCUS"."SYS_EXPORT_TABLE_01": MARCUS/******** tables=MARCUS.STGTAB_BASELINE_cvjwh9tmwcfsu directory=data_pump_dir dumpfile=STGTAB_BASELINE_cvjwh9tmwcfsu.dmp logfile=exp_STGTAB_BASELINE_cvjwh9tmwcfsu.log exclude=index,constraint,grant,trigger,statistics
Processing object type TABLE_EXPORT/TABLE/TABLE_DATA
Processing object type TABLE_EXPORT/TABLE/PROCACT_INSTANCE
Processing object type TABLE_EXPORT/TABLE/TABLE
. . exported "MARCUS"."STGTAB_BASELINE_CVJWH9TMWCFSU" 92.41 KB 9 rows
ORA-39173: Encrypted data has been stored unencrypted in dump file set.
Master table "MARCUS"."SYS_EXPORT_TABLE_01" successfully loaded/unloaded
******************************************************************************
Dump file set for MARCUS.SYS_EXPORT_TABLE_01 is:
/sapcd/enkitec/19c/STGTAB_BASELINE_cvjwh9tmwcfsu.dmp
Job "MARCUS"."SYS_EXPORT_TABLE_01" successfully completed at Wed Mar 24 20:01:56 2025 elapsed 0 00:00:14
If you need to implement this SQL Plan Baseline on a similar system,
import and unpack using these commands:
impdp userid=MARCUS tables=STGTAB_BASELINE_cvjwh9tmwcfsu directory=data_pump_dir dumpfile=STGTAB_BASELINE_cvjwh9tmwcfsu.dmp logfile=imp_STGTAB_BASELINE_cvjwh9tmwcfsu.log table_exists_action=truncate
SET SERVEROUT ON;
DECLARE
plans NUMBER;
BEGIN
plans := DBMS_SPM.UNPACK_STGTAB_BASELINE('STGTAB_BASELINE_cvjwh9tmwcfsu', 'MARCUS');
DBMS_OUTPUT.PUT_LINE(plans||' plan(s) unpackaged');
END;
/
adding: coe_load_sql_baseline.log (deflated 66%)
deleting: coe_load_sql_baseline.log
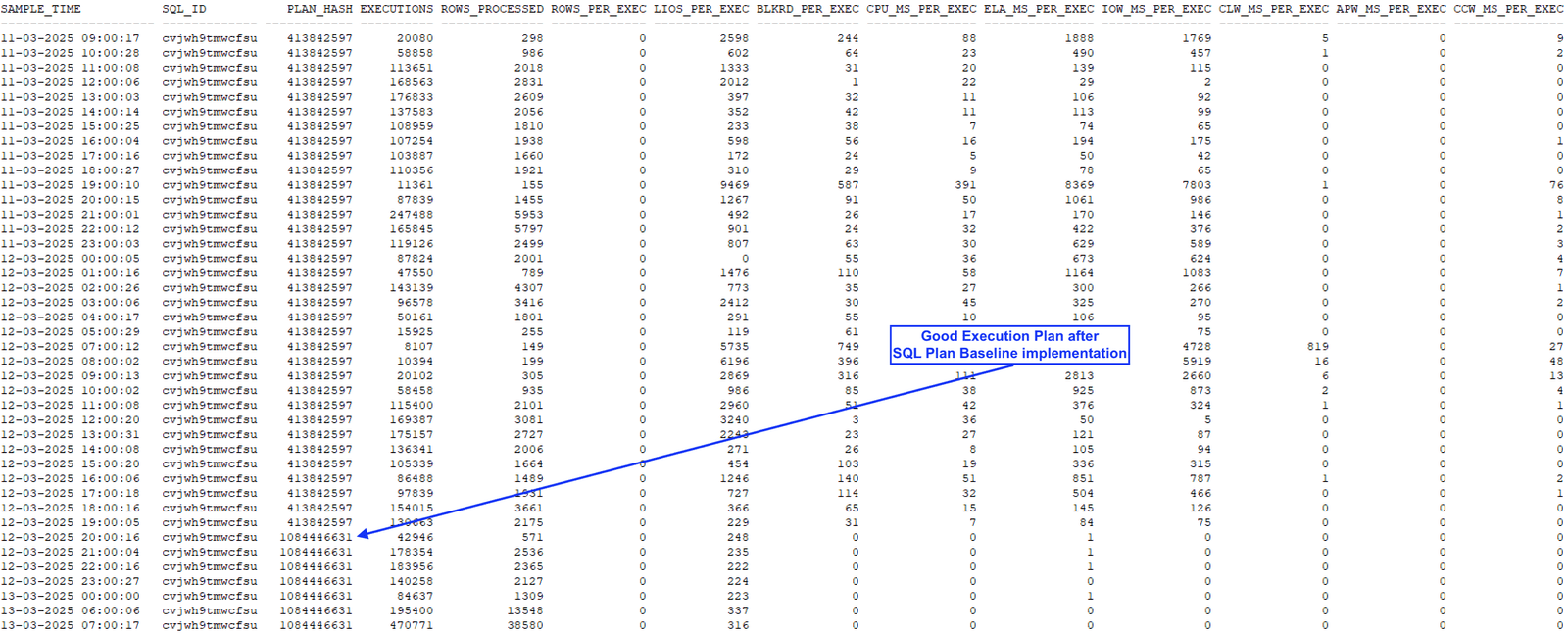
vini_coe_load_sql_baseline completed.After the creation, we can see that the new SQL_ID start using the good plan:
Hope it helps!
Peace.
Vinicius
Nice post. Can you share the sqlstats.sql?
Hi Raja,
I’ve updated the post to point to sqlstat.sql, anyway, here it is:
https://github.com/vinidba/dba_scripts/blob/master/sqlstat.sql
Thank you!
HI Vinicius,
Thank you very much for this wonderful script. Really helpful for me.
Thank you for the feedback, Nagaraju!