Hi all,
Hope you’re doing well.
Introduction:
I have a dear friend who is one of the greatest DBAs I’ve had the pleasure of working with during my career. Four years ago, he decided to step away from the IT world and become an entrepreneur in the food industry (he makes the best gelato I’ve ever had in my life!) – but he still loves technology, even though he claims he doesn’t.
Recently, he started creating a tool using C# for his business and decided to store the data in an Autonomous Database ATP using the Free Tier account. Cool, isn’t it?
The Backup Challenge:
As he has been out of the IT world for the last four years, he mentioned that he would like to set up a process to ensure he can recover his data. As one of the best DBAs, he knows the ideal backup/restore approach would be to use the automated backup that Autonomous offers. However, since he is using the Free Tier account, he is fine with performing a logical backup — the data will not consume much space, and the change rate will not be like that of an online system.
Here’s what he wants to do:
- Create a DataPump export for his main schema in the DATA_PUMP_DIR object directory
- Copy the dump file and the log file to an Object Storage Bucket.
- Apply a retention policy to keep the files for the last 3 days in the DATA_PUMP_DIR, then remove the files older than 3 days.
- Apply a retention policy to keep the files for the last 30 days in the Object Storage Bucket, then remove the files older than 30 days.
Prerequisites:
- Generate an Auth Token for his account on OCI.
- Create an Object Storage Bucket on his Tenancy.
- Create a CREDENTIAL inside the Database using the Auth Token generated.
- Create a PL/SQL Procedure that will implement the following steps:
- Create a DataPump export for his main schema in the DATA_PUMP_DIR object directory
- Copy the dump file and the log file to an Object Storage Bucket.
- Apply a retention policy to keep the files for the last 3 days in the DATA_PUMP_DIR, and then, remove the files older than 3 days.
- Create a Scheduler Job Class to set the log history retention to 30 days and the logging level to full.
- Create a Scheduler Job to execute the PL/SQL Procedure daily and to use the job class previously created.
- Create an IAM Policy to allow the service objectstorage in his home region to manage the Object Storage family in the tenancy.
- Create an Object Storage Bucket Lifecycle Policy Rule to delete the files older than 30 days in the Object Storage Bucket.
Generating the Auth Token:
From the initial page of OCI Console in the top right corner, click on the button to go to your profile/account:

Then, click in the first link, to go to your profile/account:
Now that you are in your profile, click on Tokens and keys:
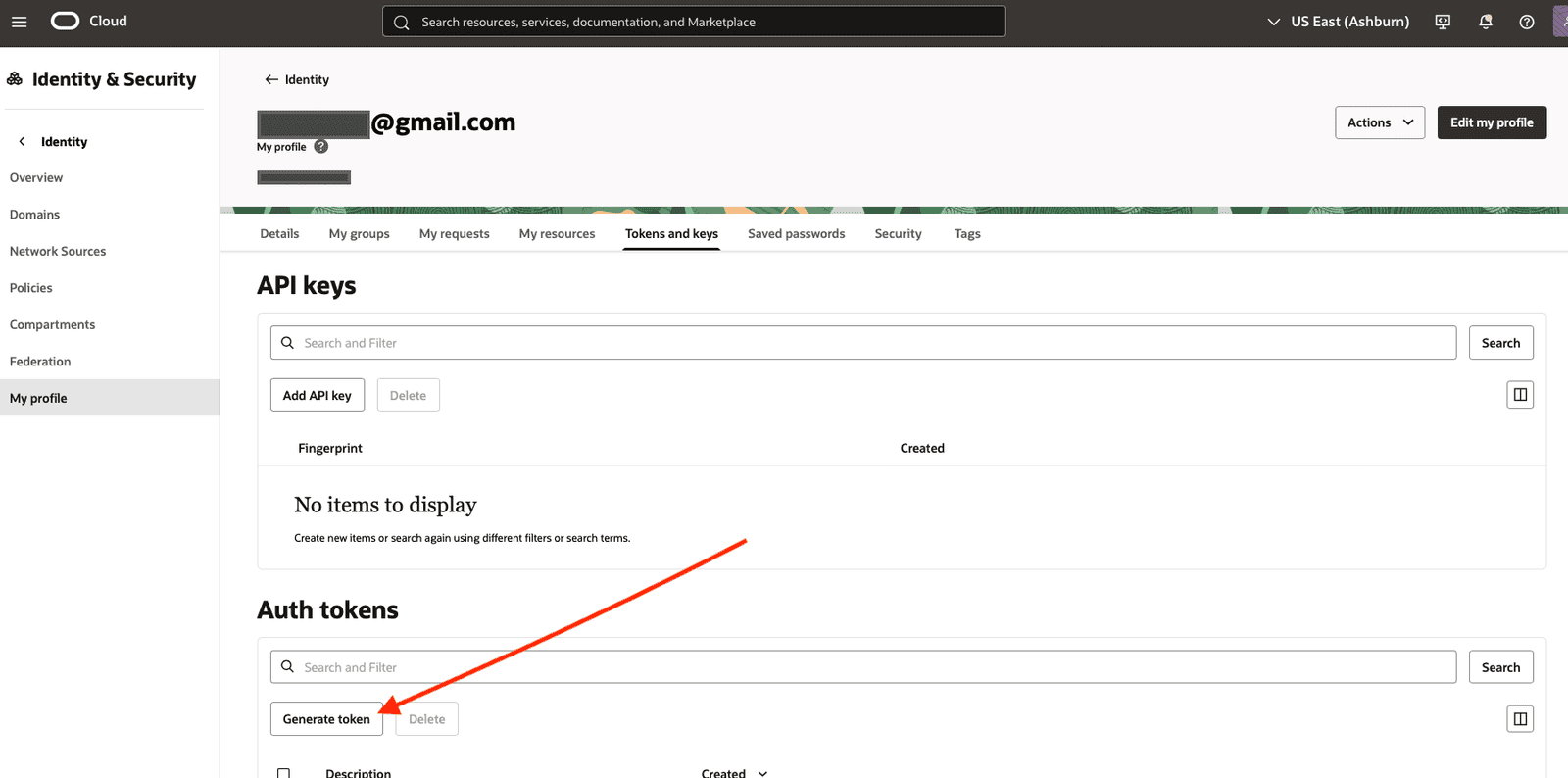
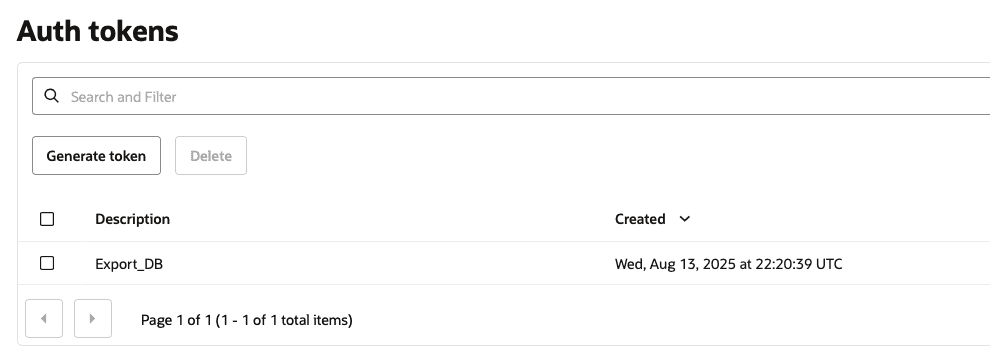
Under Auth tokens section, click on Generate token button:
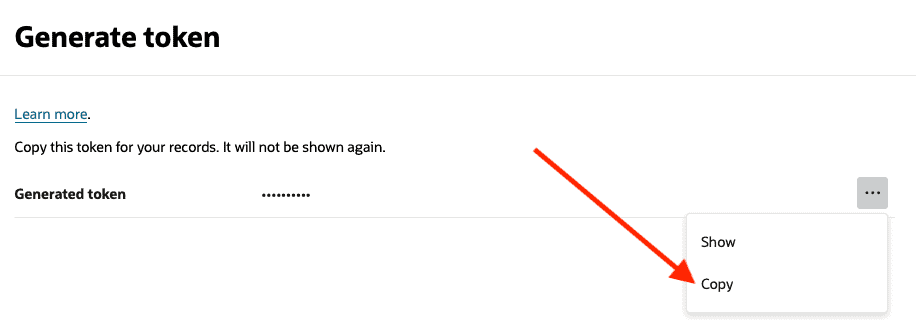
You can specify a name for your token. This name will not be used in any place, but it’s good to create the token with a name that you can identify it in the future in case you want to delete it. After specify the name, click on Generate token button:

Once the Auth token is generated, you can click on the three dots button to show or to copy the token. Keep in mind that this token will not be shown again. So, make sure to copy the token, we will need it during the DB CREDENTIAL creation:
Now you can see the Token you just generated:
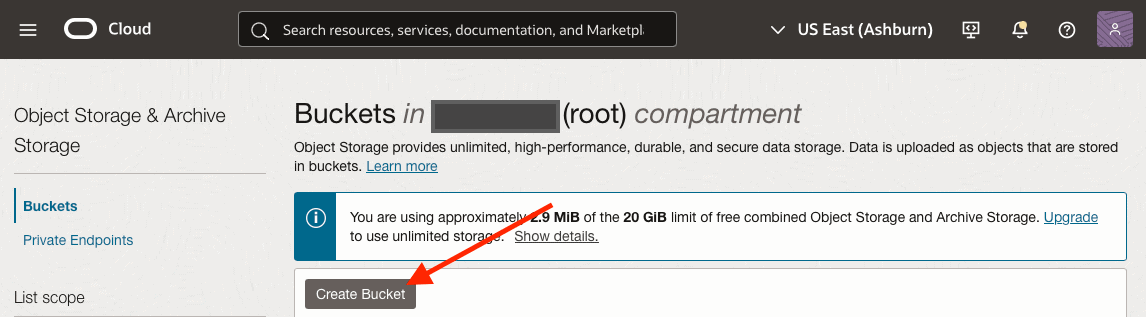
Creating the Object Storage Bucket:
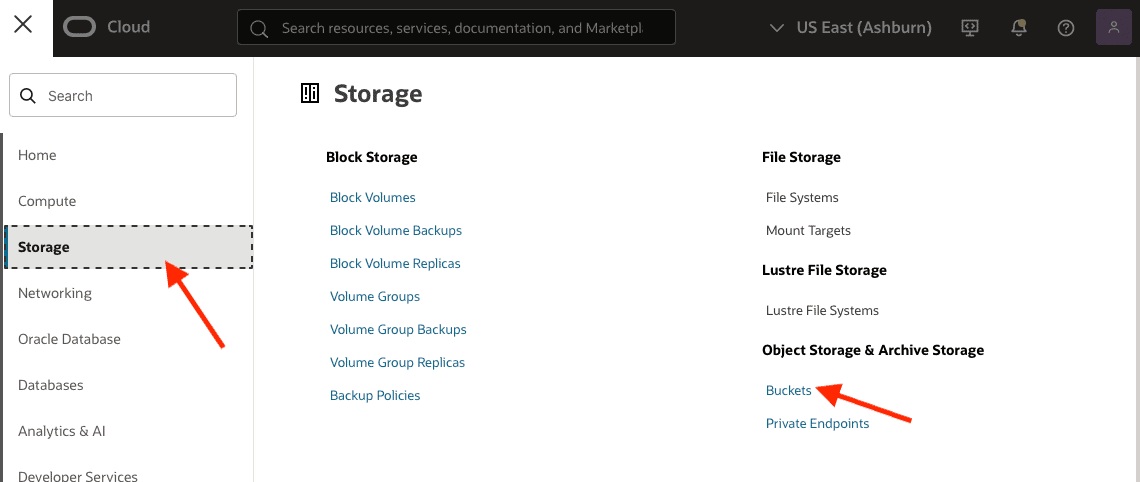
Now, in the hamburger menu (top left), click on Storage and then, on Buckets:
Click on Create Bucket:
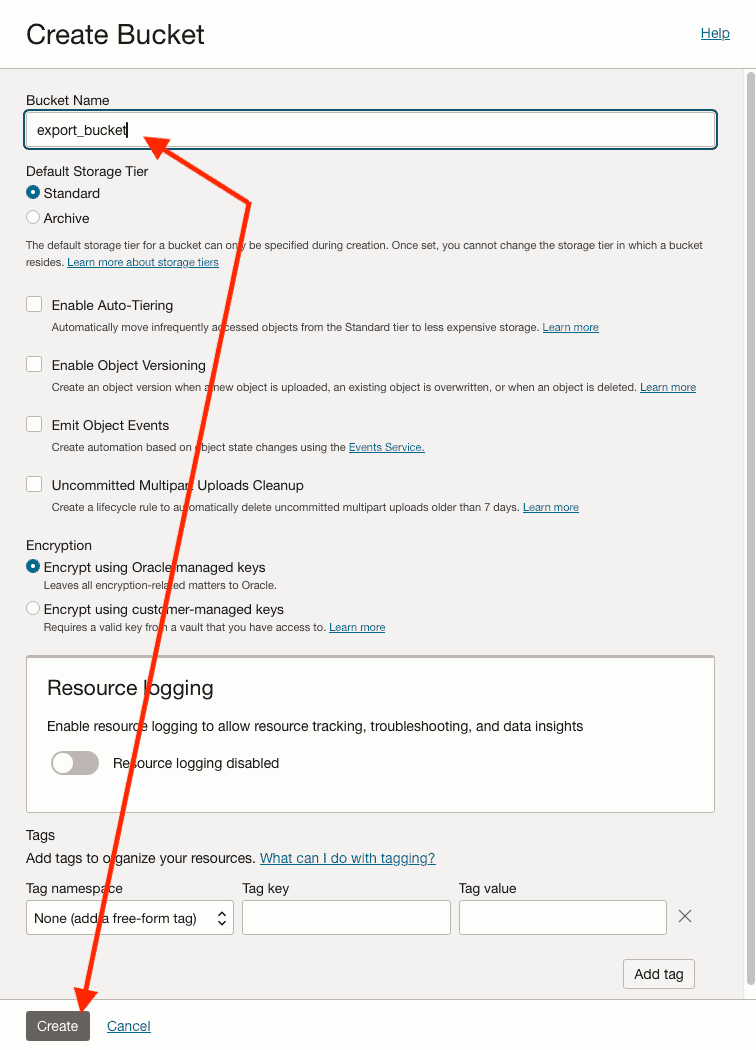
Under Create Bucket, specify a name and click on Create. This name will be used later in the Database, so, it’s best to choose one that clearly indicates its purpose and will be easy to recognize it in the future:
Now we have the bucket created. Click on the bucket to see the details:
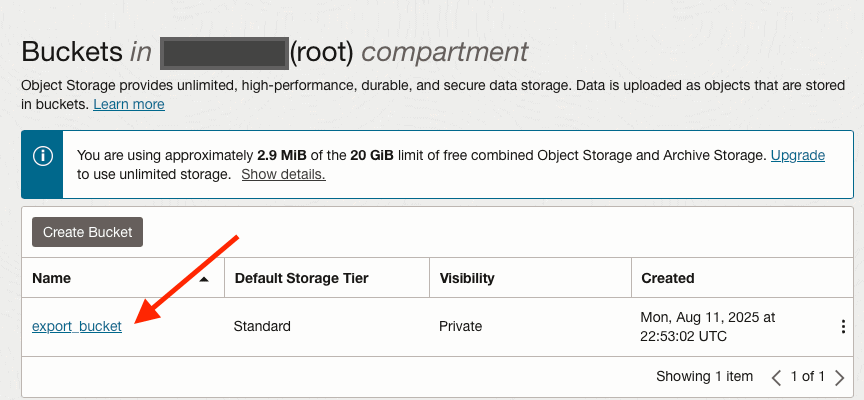
Under the bucket details, we need to copy the Namespace (first field) along with the Bucket name, export_bucket:
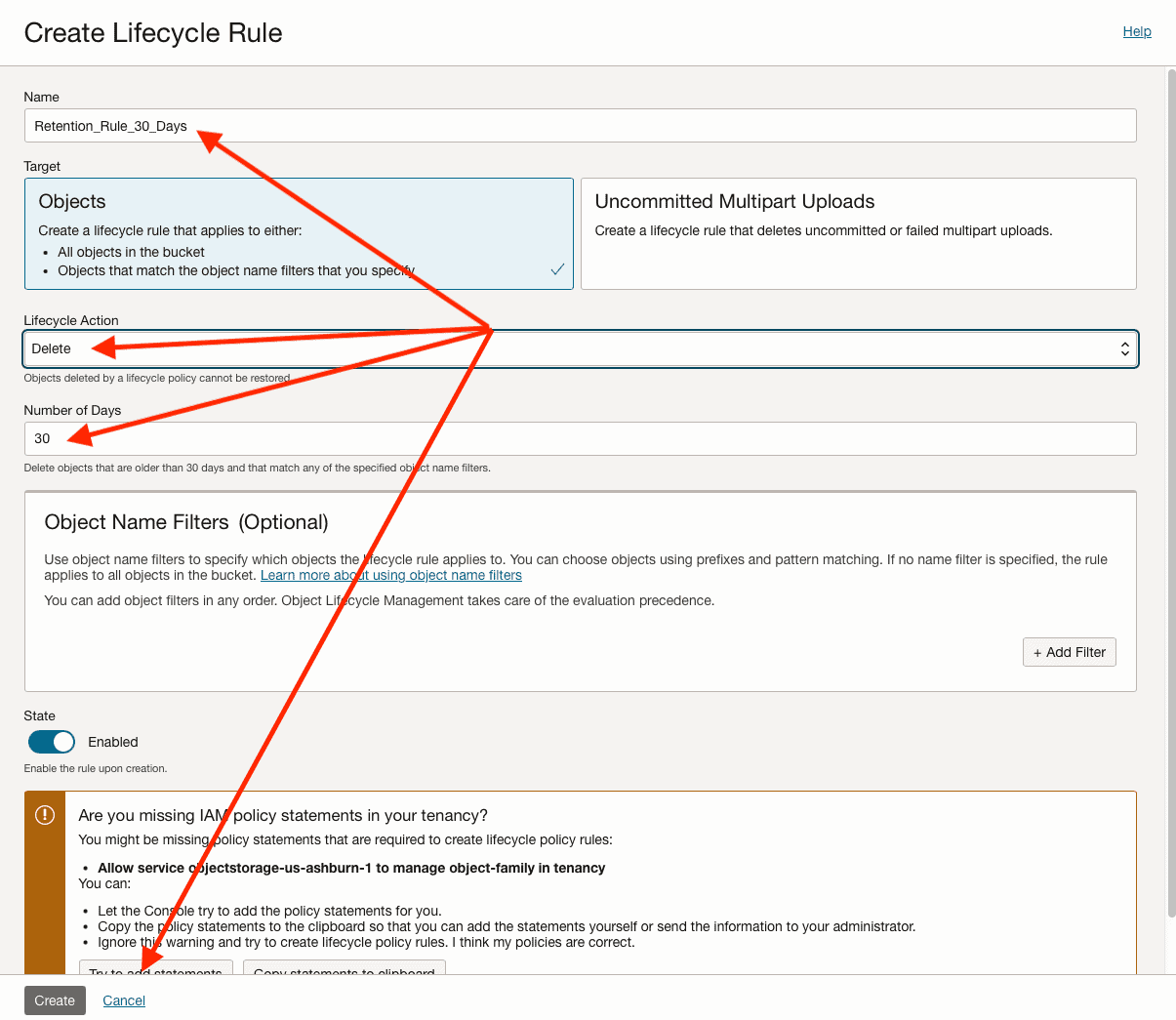
Creating the Object Storage Bucket Lifecycle Policy Rule:
In the same page you are, under Bucket details, in the bottom left, create on Lifecycle Policy Rules:

Click on Create Rule button:

Now you need to:
- Specify a name for your rule.
- Specify the Delete as the Lifecycle Action.
- Specify the Number of Days for your desired retention.
- Click on “Try to add statements” to create the IAM Policy to allow objectstorage in your home region o manage the object-family in your tenancy:
Under Add IAM Policy, you can specify a name if you want it, then, click on Create:
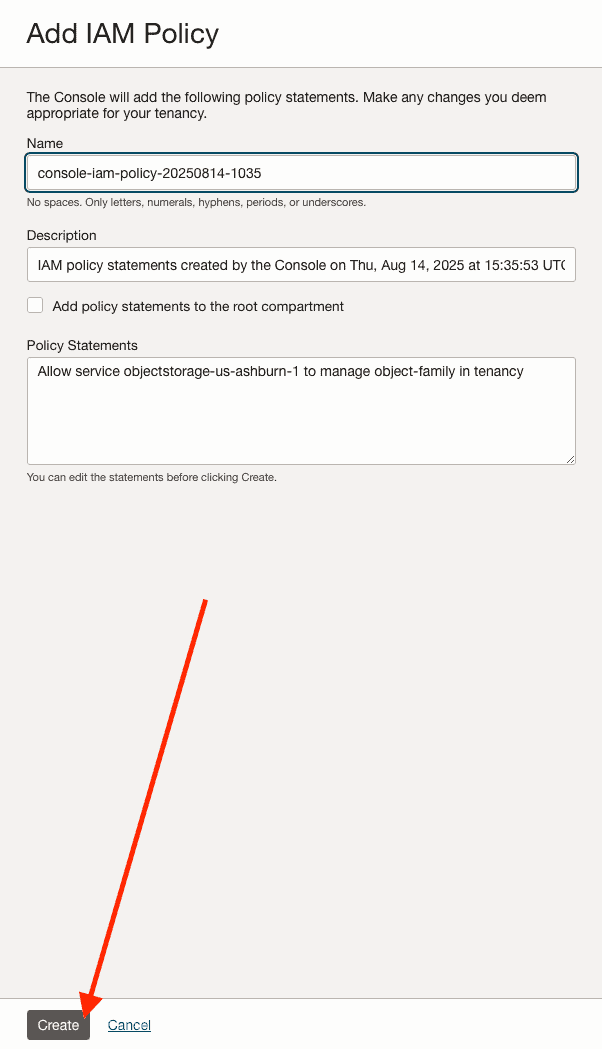
We can see that the IAM Policy has been created with no issues. Now click on Create to create the Lifecycle Rule:
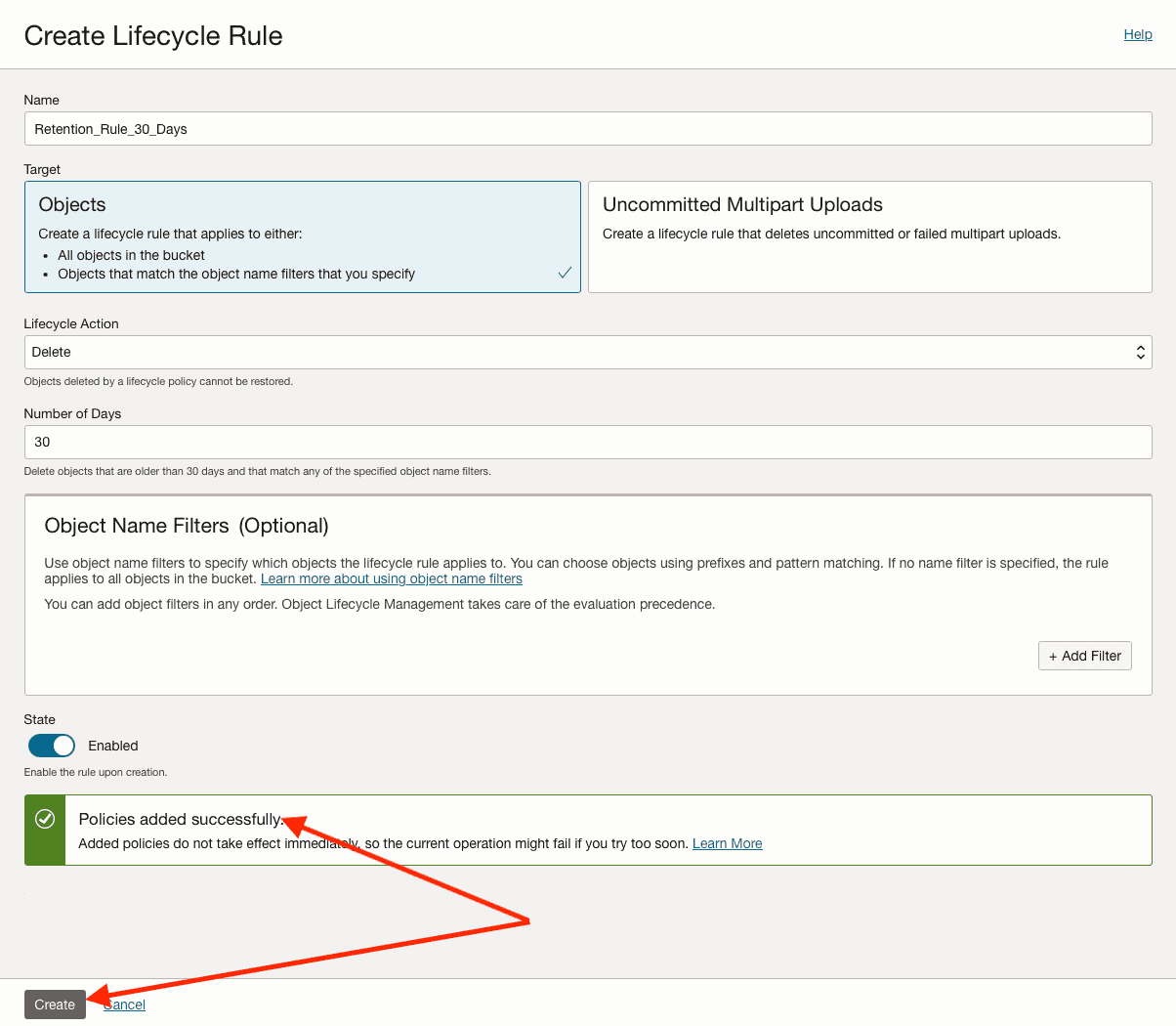
In the below screen we can see our Lifecycle Rule created:

Creating the CREDENTIAL in the Database:
I will not show demonstrate how to connect to your Autonomous Database, as there are plenty of blog posts and articles on the Internet covering that topic. You can follow the official Oracle documentation here:
https://docs.oracle.com/en-us/iaas/autonomous-database-serverless/doc/connect-sql-dev182.html
Once you are connected to your database, you can create the CREDENTIAL.
For security reasons, I will mask the original value here.
Basically, you will need to provide the following fields:
- CREDENTIAL Name.
- Your OCI username.
- Your Auth token – the one you copied when you generated it:
begin
dbms_cloud.create_credential (
credential_name => 'OBJ_STORAGE_CRED',
username => 'myuser@gmail.com',
password => 'my_auth_token_that_I_copied'
) ;
end;
/Creating the PL/SQL Procedure in the Database:
Now it’s time to create our PL/SQL Procedure.
This Procedure will implement the following steps to our job:
- Create a DataPump export for the main schema in the DATA_PUMP_DIR object directory
- Copy the dump file and the log file to an Object Storage Bucket.
- Apply a retention policy to keep the files for the last 3 days in the DATA_PUMP_DIR, removing the files older than 3 days.
We will need some information we have copied in the previous steps along with some additional information that is required:
- The Object Storage uri.
- The prefix for the Data Pump dump and log files, which will be APPGELATO.
- The directory object, which in our case is DATA_PUMP_DIR.
- The schema name, which is APPGELATO.
- The CREDENTIAL name, which is OBJ_STORAGE_CRED.
We will need the Object Storage uri, which is basically this:
https://swiftobjectstorage.your-region.oraclecloud.com/v1/bucket_namespace/bucket_name/
For security reasons, I will mask the namespace (we copied this in the previous steps). But my uri, will most likely be:
https://swiftobjectstorage.us-ashburn-1.oraclecloud.com/v1/omqfjuta9ftt/export_bucket/
This is the code for our Procedure:
create or replace PROCEDURE EXPORT_APPGELATO_SCHEMA
AUTHID CURRENT_USER
AS
l_dp_handle NUMBER;
l_dp_out VARCHAR2(30);
l_current_date VARCHAR2(8);
l_dump_filename VARCHAR2(100);
l_log_filename VARCHAR2(100);
l_file_count NUMBER := 0;
l_upload_count NUMBER := 0;
BEGIN
-- Get current date in YYYYMMDD format
l_current_date := TO_CHAR(SYSDATE, 'YYYYMMDD');
-- Set filenames with current date
l_dump_filename := 'exp_APPGELATO_' || l_current_date || '.dmp';
l_log_filename := 'exp_APPGELATO_' || l_current_date || '.log';
DBMS_OUTPUT.PUT_LINE('Starting export for date: ' || l_current_date);
DBMS_OUTPUT.PUT_LINE('Dump file: ' || l_dump_filename);
DBMS_OUTPUT.PUT_LINE('Log file: ' || l_log_filename);
-- Step 1: Open a schema export job
l_dp_handle := DBMS_DATAPUMP.OPEN(
operation => 'EXPORT',
job_mode => 'SCHEMA',
remote_link => NULL,
job_name => 'APPGELATO_EXPORT_' || l_current_date,
version => 'LATEST');
-- Specify the dump file name and directory object name
DBMS_DATAPUMP.ADD_FILE(
handle => l_dp_handle,
filename => l_dump_filename,
directory => 'DATA_PUMP_DIR');
-- Specify the log file name and directory object name
DBMS_DATAPUMP.ADD_FILE(
handle => l_dp_handle,
filename => l_log_filename,
directory => 'DATA_PUMP_DIR',
filetype => DBMS_DATAPUMP.KU$_FILE_TYPE_LOG_FILE);
-- Specify the schema to be exported
DBMS_DATAPUMP.METADATA_FILTER(
handle => l_dp_handle,
name => 'SCHEMA_EXPR',
value => '= ''APPGELATO''');
-- Start the job
DBMS_DATAPUMP.START_JOB(l_dp_handle);
-- Wait for job completion
DBMS_DATAPUMP.WAIT_FOR_JOB(l_dp_handle, l_dp_out);
DBMS_OUTPUT.PUT_LINE('Export job completed with status: ' || l_dp_out);
-- Step 2: Confirm files were created today
SELECT COUNT(*)
INTO l_file_count
FROM DBMS_CLOUD.LIST_FILES('DATA_PUMP_DIR')
WHERE TRUNC(CREATED) = TRUNC(SYSDATE);
DBMS_OUTPUT.PUT_LINE('Files found for today: ' || l_file_count);
IF l_file_count = 0 THEN
RAISE_APPLICATION_ERROR(-20001, 'No files were created today. Export may have failed.');
END IF;
-- Step 3: Upload files to Oracle Cloud Object Storage
FOR r IN (
SELECT object_name
FROM DBMS_CLOUD.LIST_FILES('DATA_PUMP_DIR')
WHERE TRUNC(CREATED) = TRUNC(SYSDATE)
) LOOP
BEGIN
DBMS_CLOUD.PUT_OBJECT(
credential_name => 'OBJ_STORAGE_CRED',
object_uri => 'https://swiftobjectstorage.us-ashburn-1.oraclecloud.com/v1/omqfjuta9ftt/export_bucket/' || r.object_name,
directory_name => 'DATA_PUMP_DIR',
file_name => r.object_name
);
l_upload_count := l_upload_count + 1;
DBMS_OUTPUT.PUT_LINE('Successfully uploaded: ' || r.object_name);
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Error uploading ' || r.object_name || ': ' || SQLERRM);
END;
END LOOP;
DBMS_OUTPUT.PUT_LINE('Upload completed. Total files uploaded: ' || l_upload_count);
-- Step 4: Clean up local files
FOR r IN (
SELECT object_name
FROM DBMS_CLOUD.LIST_FILES('DATA_PUMP_DIR')
WHERE TRUNC(CREATED) = TRUNC(SYSDATE) - 3
) LOOP
BEGIN
UTL_FILE.FREMOVE('DATA_PUMP_DIR', r.object_name);
DBMS_OUTPUT.PUT_LINE('Removed local file: ' || r.object_name);
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Error removing ' || r.object_name || ': ' || SQLERRM);
END;
END LOOP;
COMMIT;
DBMS_OUTPUT.PUT_LINE('Procedure completed successfully.');
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Error in procedure: ' || SQLERRM);
-- Clean up Data Pump handle if it exists
IF l_dp_handle IS NOT NULL THEN
BEGIN
DBMS_DATAPUMP.STOP_JOB(l_dp_handle);
EXCEPTION
WHEN OTHERS THEN
NULL;
END;
END IF;
RAISE;
END;
/Please note that I am creating the Procedure with invoker’s right using AUTHID CURRENT_USER. This is required to avoid the issue: ORA-31631 as mentioned in the My Oracle Support Note ORA-31631 When Calling DBMS_DATAPUMP API Using TRACE From Package (Doc ID 1577107.1).
Creating the Scheduler Job Class and Scheduler Job:
Now it’s time to create our Scheduler Job Class and our Scheduler Job.
The Scheduler Job Class will be created to set the logging level to full and the log retention to 30 days.
The Scheduler Job will be created to use the Scheduler Job Class we are creating and to execute the PL/SQL Procedure we created and to specify that the Job will be executed daily at 12:30 pm.
Here is the code:
BEGIN
-- Create a job class with 30-day retention
DBMS_SCHEDULER.CREATE_JOB_CLASS(
job_class_name => 'APPGELATO_EXPORT_CLASS',
resource_consumer_group => 'DEFAULT_CONSUMER_GROUP',
service => NULL,
logging_level => DBMS_SCHEDULER.LOGGING_FULL,
log_history => 30,
comments => 'Job class for APPGELATO schema export jobs with 30-day retention'
);
DBMS_OUTPUT.PUT_LINE('Job class APPGELATO_EXPORT_CLASS created successfully');
-- Create the job using the custom job class
DBMS_SCHEDULER.CREATE_JOB(
job_name => 'APPGELATO_DAILY_EXPORT',
job_type => 'STORED_PROCEDURE',
job_action => 'EXPORT_APPGELATO_SCHEMA',
number_of_arguments => 0,
start_date => SYSTIMESTAMP,
repeat_interval => 'FREQ=DAILY; BYHOUR=12; BYMINUTE=30',
end_date => NULL,
job_class => 'APPGELATO_EXPORT_CLASS', -- Use our custom job class
enabled => TRUE,
auto_drop => FALSE,
comments => 'Daily APPGELATO schema export at 12:30 PM with 30-day history retention'
);
DBMS_OUTPUT.PUT_LINE('Job created successfully using custom job class');
-- Configure individual job attributes
DBMS_SCHEDULER.SET_ATTRIBUTE(
name => 'APPGELATO_DAILY_EXPORT',
attribute => 'store_output',
value => TRUE
);
DBMS_SCHEDULER.SET_ATTRIBUTE(
name => 'APPGELATO_DAILY_EXPORT',
attribute => 'logging_level',
value => DBMS_SCHEDULER.LOGGING_FULL
);
DBMS_OUTPUT.PUT_LINE('Job attributes configured: store_output=TRUE, logging_level=FULL');
DBMS_OUTPUT.PUT_LINE('Job creation and configuration completed successfully');
END;
/Checking the Scheduler Job execution:
After creating the Scheduler Job Class and the Scheduler Job, let’s see if the job has been executed with no errors:
SELECT LOG_ID,LOG_DATE,OWNER,JOB_NAME,OPERATION,STATUS FROM dba_scheduler_job_log WHERE OPERATION='RUN' AND JOB_NAME='APPGELATO_DAILY_EXPORT';
Here is the output:

We can see the details if we want:
SELECT LOG_ID,LOG_DATE,OWNER,JOB_NAME,STATUS,RUN_DURATION,OUTPUT FROM dba_scheduler_job_run_details WHERE JOB_NAME='APPGELATO_DAILY_EXPORT';
Here is the output:

If we want, we can check the current content of DATA_PUMP_DIR:
SELECT *
FROM DBMS_CLOUD.LIST_FILES('DATA_PUMP_DIR');Here is the output:

Great!
Checking the Object Storage content:
We can check the content of our Object Storage Bucket:
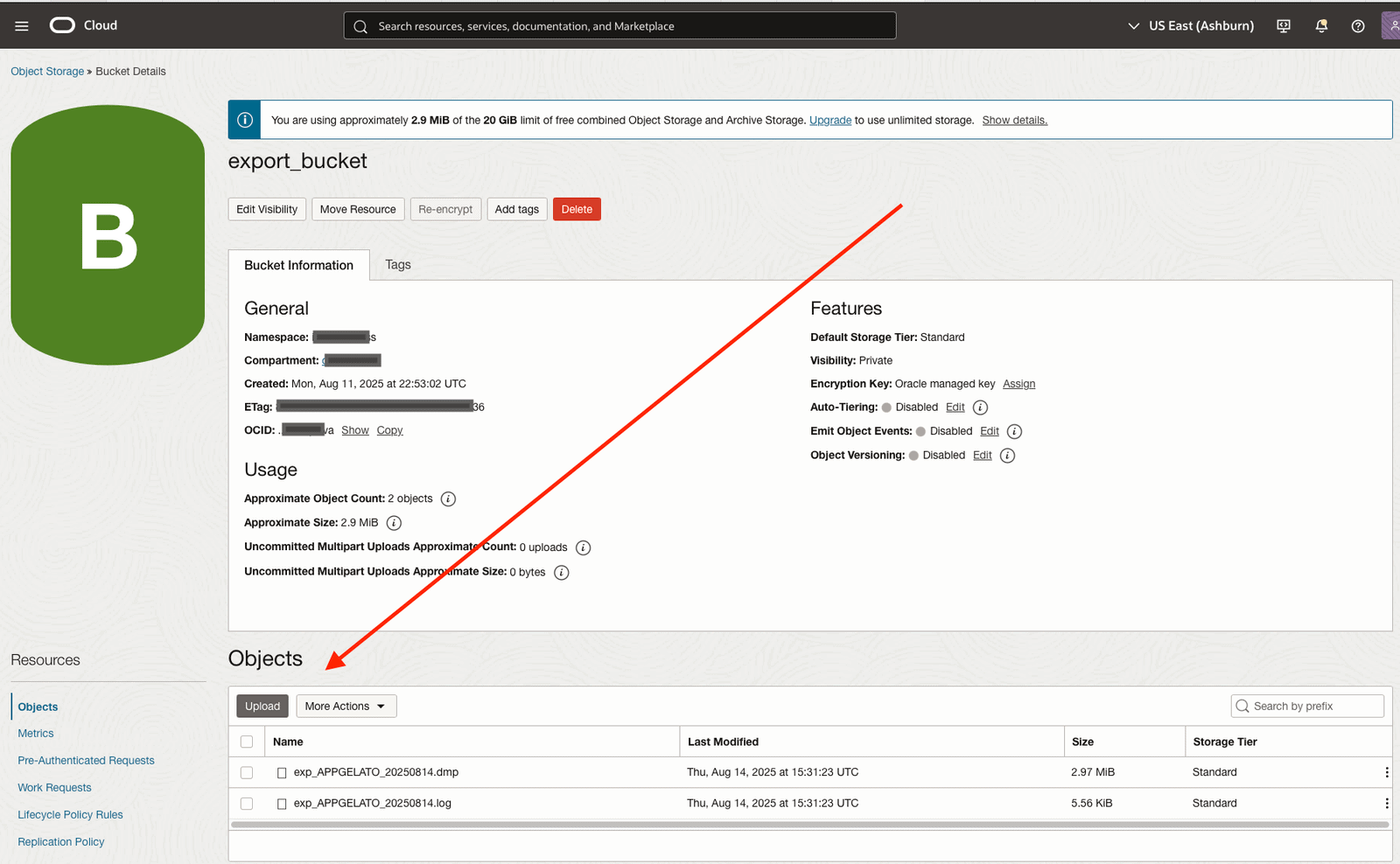
So, that’s it – mission accomplished!
This was a long post to write, and I hope it is useful for you!
Peace!
Vinicius
[…] Autonomous DB and OCI: Exporting a Schema to Object Storage + Retention Policy – Marcus Vinicius gives you a detailed guide to back up your ADB schema to object […]