
Some weeks ago, a client called complaining about a slowness during its load in a table.
The scenario it was pretty simple:
- INSERT of thousands of records;
- Direct-Path INSERT, using the hint APPEND_VALUES;
- No INSERT with subquery involved.
They are loading the table using the INSERT statement for each agency (agency_id), with thousands of records for each agency. They complained that each agency was taking more than 20 minutes to load the data.
As first thing, I verified the waiting sessions on DB and found that the user was waiting on ‘db file sequential read’ wait event for their INSERT statement (info obfuscated for security reasons):

The query above was a result of joining GV$INSTANCE, GV$SESSION and GV$SESSION_WAIT dictionary views. You can download it from here: waiting_sessions.sql
As we can see, we have an INSERT statement waiting on ‘db file sequential read’. The LAST_CALL_ET column shows that INSERT was running for almost 3 minutes.
This is the INSERT statement:
INSERT /*+APPEND_VALUES*/ INTO USER_LOAD.TABLE_1 VALUES (COL_01,COL_02,COL_03,COL_04,COL_05,COL_06,COL_07,COL_08,COL_09,COL_10,COL_11,COL_12,COL_13,COL_14,COL_15,COL_16,COL_17,COL_18,COL_19,COL_20) VALUES (:1 ,:2 ,:3 ,:4 ,:5 ,:6 ,:7 ,:8 ,:9 ,:10 ,:11 ,:12 ,:13 ,:14 ,:15 ,:16 ,:17 ,:18 ,:19 ,:20 )
The interesting here is the wait on ‘db file sequential read’ for an INSERT statement with no subquery involved.
This event means that Oracle is reading blocks sequentially, usually as a single-block read. This wait event is often associated with index scans, but it is not limited to them.
Fortunately, there is a way to identify which object is related to this event.
The event ‘db file sequential read’ use some parameters to identify where the waiting is occurring. In the GV$SESSION_WAIT view we have the below columns. Each column correspond to a specific structure in Oracle:
- P1: file#;
- P2: block#.
We also have the column P3, which shows how many blocks were read from the starting block# identified on P2 and starting file# identified on P1.
A brief explanation for each column:
| file# | block# |
| This is the file# of the file that Oracle is trying to read from. From Oracle8 onwards it is the ABSOLUTE file number (AFN). | This is the starting block number in the file from where Oracle starts reading the blocks. Typically only one block is being read. |
So, we do know the values for P1 and P2:
- P1: 1949;
- P2: 3462037.
There is a query that we can use the file# and block# to identify the segment associated with those values:
SET LINES 200
COLUMN OWNER FORMAT A15
COLUMN SEGMENT_TYPE FORMAT A8
COLUMN SEGMENT_NAME FORMAT A30
SELECT owner , segment_name , segment_type
FROM dba_extents
WHERE file_id = 1949
AND 3462037 BETWEEN block_id AND block_id + blocks -1;
OWNER SEGMENT_NAME SEGMENT_TYPE
———– ————- ————
OWNER_OBJ IDX_TABLE_1_1 INDEX
Perfect, we were able to identify that this is an INDEX. Before we discuss about this, let’s also explore further other options to conclude the same. 🙂
We do know that the SID is 1114. There is a way to enable the trace for this session using ORADEBUG. Let’s do it. Below we have some queries and commands that will help us to “attach” to session, enable the trace and also identify which is the trace file:
select ‘ORADEBUG SETORAPID ‘||pid||’;’
from v$process
where addr = (select paddr from v$session where sid = 1114);
ORADEBUG SETORAPID 155;
ORADEBUG SETORAPID 155;
Oracle pid: 193, Unix process pid: 32148, image: oracle@DBSERVER1
ORADEBUG TRACEFILE_NAME;
/oracle/app/oracle/diag/rdbms/db_rac/INST1/trace/INST1_ora_19955.trc
ORADEBUG EVENT 10046 TRACE NAME CONTEXT FOREVER, LEVEL 12;
Statement processed.
Summarizing what we did with the commands above:
- I generated the command to “attach” to the session;
- Copied and pasted the command to attach to the session;
- Identified the trace file;
- Enabled the SQL trace for the session.
Now that the trace is enabled and INSERT is still running, let’s see what is going on, I’m simply executed this command:
tail -200f /oracle/app/oracle/diag/rdbms/db_rac/INST1/trace/INST1_ora_19955.trc
Here is the output for the command:
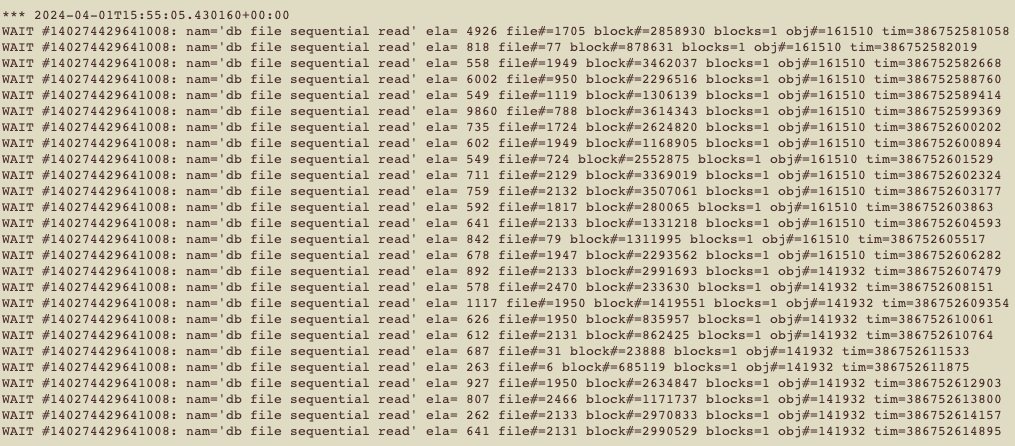
As we can clearly see, we have lots of WAITS on ‘db file sequential read’. OK, you can see some information in the trace. We have a column called obj#, which is the OBJECT_ID. So, it’s easy to check that is the object associated with wait 😉
SET LINES 200
COLUMN OWNER FORMAT A15
COLUMN OWNER_TYPE FORMAT A8
COLUMN OBJECT_NAME FORMAT A30
SELECT owner,object_id,object_name,object_type
FROM dba_objects
WHERE object_id = 141932;
OWNER OBJECT_ID OBJECT_NAME OBJECT_TYPE
———– ——— ————- ————
OWNER_OBJ 141932 IDX_TABLE_1_1 INDEX
See? We were able to identify the same object!
OK, great, now, let’s understand why is the INSERT statement slow and what is the role of ‘db file sequential read’ on this.
First, let’s understand what is an INDEX:
Indexes are optional structures associated with tables and clusters that allow SQL queries to execute more quickly against a table.
Just as the index in a book helps you locate information faster than if there were no index, an Oracle Database index provides a faster access path to table data. You can use indexes without rewriting any queries. Your results are the same, but you see them more quickly.
Oracle Database provides several indexing schemes that provide complementary performance functionality.
You can read more about index in Oracle here: Database Administrator’s Guide – 21 Managing Indexes – About Indexes
In the same documentation, we have this:
“The database automatically maintains indexes when you insert, update, and delete rows of the associated table. If you drop an index, all applications continue to work. However, access to previously indexed data might be slower.”
Interesting, isn’t?
We also have another interesting part in this document: Database Performance Tuning Guide – 2 Designing and Developing for Performance – Finding the Cost of an Index
“Building and maintaining an index structure can be expensive, and it can consume resources such as disk space, CPU, and I/O capacity. Designers must ensure that the benefits of any index outweigh the negatives of index maintenance.
Use this simple estimation guide for the cost of index maintenance: each index maintained by an INSERT, DELETE, or UPDATE of the indexed keys requires about three times as much resource as the actual DML operation on the table. Thus, if you INSERT into a table with three indexes, then the insertion is approximately 10 times slower than an INSERT into a table with no indexes. For DML, and particularly for INSERT-heavy applications, the index design should be seriously reviewed, which might require a compromise between the query and INSERT performance.”
So, let’s ask again:
Why is the INSERT statement slow and what is the role of ‘db file sequential read’ on this?
It doesn’t it matter if we are only running INSERT on table. The index structure must be maintained. So, ‘db file sequential read’ during an INSERT statement happens because of the index maintenance.
The only way to avoid waits on ‘db file sequential read’ during INSERT is dropping the indexes or making them unusable. This is something that you must decide along with your app architect and team involved on this business, because if you drop or make the indexes unusable, you must consider the time to create or rebuild the indexes.
Keep in mind that if index is unusable, the query that previously was optimized due the index, now maybe will run slower due a full table scan operation. Not only this, if the parameter SKIP_UNUSABLE_INDEXES is set to FALSE, your DML (INSERT, UPDATE or DELETE) or even your SELECT should fail with the error: ORA-01502: index ‘schema.index_name’ or partition of such index is in unusable state.
For this client on this specific situation, this load will happens only once and they were being severely impacted by the indexes maintenance during INSERT. We decided to make the indexes unusable. This allow us to reduce the time spent on INSERT from 23 minutes to 50 seconds. Of course, when all the data was loaded to the table and BEFORE we release the DB to application, we did the rebuild on indexes.
Also, some Data Warehouse solutions use this approach: drop index, load data, create index – to optimize their data loads. But again, this needs to be well discussed with all stakeholders to avoid any issue.
Below there is a simple test case where we can see the behavior in an INSERT statement BEFORE and AFTER we create indexes in the table.
Let’s first create a table:
CREATE TABLE example_table (
id NUMBER,
name VARCHAR2(50),
age NUMBER,
email VARCHAR2(100)
);
Now, let’s run the INSERT for one million of records:
DECLARE
v_counter NUMBER := 1;
BEGIN
WHILE v_counter <= 1000000 LOOP
INSERT INTO /*+APPEND_VALUES */ example_table (id, name, age, email)
VALUES (v_counter, 'Name'||v_counter, TRUNC(DBMS_RANDOM.VALUE(18, 80)), 'email'||v_counter||'@example.com');
v_counter := v_counter + 1;
IF MOD(v_counter, 1000) = 0 THEN
COMMIT;
END IF;
END LOOP;
COMMIT;
END;
/During the execution of INSERT, run the query waiting_sessions.sql in another session:

Perfect, no wait on ‘db file sequential read’.
Now, let’s create some indexes in the table:
CREATE INDEX MARCUS.IX01 ON MARCUS.EXAMPLE_TABLE(ID);
Index created.
CREATE INDEX MARCUS.IX02 ON MARCUS.EXAMPLE_TABLE(NAME);
Index created.
CREATE INDEX MARCUS.IX03 ON MARCUS.EXAMPLE_TABLE(AGE);
Index created.
CREATE INDEX MARCUS.IX03 ON MARCUS.EXAMPLE_TABLE(EMAIL);
Index created.
Now, let’s run the INSERT again:
DECLARE
v_counter NUMBER := 1;
BEGIN
WHILE v_counter <= 1000000 LOOP
INSERT INTO /*+APPEND_VALUES */ example_table (id, name, age, email)
VALUES (v_counter, 'Name'||v_counter, TRUNC(DBMS_RANDOM.VALUE(18, 80)), 'email'||v_counter||'@example.com');
v_counter := v_counter + 1;
IF MOD(v_counter, 1000) = 0 THEN
COMMIT;
END IF;
END LOOP;
COMMIT;
END;
/During the execution of INSERT, run the query waiting_sessions.sql in another session again:

Great! We were able to reproduce! We also have values for P1 and P2, let’s check:
There is a query that we can use the file# and block# to identify the segment associated with those values:
SET LINES 200
COLUMN OWNER FORMAT A15
COLUMN SEGMENT_TYPE FORMAT A8
COLUMN SEGMENT_NAME FORMAT A30
SELECT owner , segment_name , segment_type
FROM dba_extents
WHERE file_id = 126
AND 1504534 BETWEEN block_id AND block_id + blocks -1;
OWNER SEGMENT_NAME SEGMENT_TYPE
———– ————- ————
MARCUS IX04 INDEX
As we can see, the segment where we have ‘db file sequential read’ is the index we created earlier.
So, I don’t want to be repetitive, but, let’s wrap up this blog post.
Facts and Conclusion:
- INSERT of thousands of records;
- Table have some indexes;
- Session waiting for ‘db file sequential read’;
- Waiting is associated with index maintenance during INSERT;
- You must check carefully if you will drop the index (or make it unusable);
- If you drop the index (or make it unusable), the INSERT will speed up as we’ll no have waits for ‘db file sequential read’;
- If the parameter SKIP_UNUSABLE_INDEXES is set to TRUE, the queries that were using the index before, now probably will perform a full table scan, leading to an impact in performance;
- If parameter SKIP_UNUSABLE_INDEXES is set to FALSE, you are most likely face the error: ORA-01502: index ‘schema.index_name’ or partition of such index is in unusable state.
- If you drop (or make it unusable) an index, remember to create or rebuild it once the data load is done if the index is still required for performance on your queries.
Hope it helps!
Peace!
Vinicius


